Data mesh is still in its infancy, and data personas and organizations are craving clarity and specificity. It is critical to be aware of the "why” and “what” and fully understand the role that knowledge graphs play when considering adopting a data mesh strategy.
The debate on what constitutes a data mesh rages on. Most agree that it is not a platform or a commercial off-the-shelf product and that it should make data more accessible, secure, discoverable, and interoperable. But beyond the confusion of what it is, there are also the challenges of understanding the processes and data connections needed to deliver on a data mesh effort. Clarifying what data mesh is and how it works is important, but even more so is starting with the why.
Why Organizations Need A Data Mesh
The data mesh paradigm aims to address some of the biggest pain points for most organizations. One of these is scaling enterprise data infrastructure to incorporate different data types from various sources. This becomes particularly problematic when dealing with veracity of data. Data mesh solves this by promoting data autonomy, allowing users to make decisions about domains without a centralized gatekeeper. It also improves development velocity with better data governance and access with improved data quality aligned with business needs.
The inability to establish a domain-centric sense of data ownership that is often far removed from the business understanding of data is another common challenge, making it hard for organizations to leverage their data as a strategic asset. A mesh approach helps distribute data ownership and reduce dependencies between services, creating an environment that promotes data-driven thinking.
Coordinating and communicating effectively across cross-functional teams is another challenge, and often the root of failures as the gap between data and the business widens. By allowing organizational autonomy between teams, data mesh eliminates central bottlenecks and delivers value from data.
Figure 1 Shows the overall idea of a data mesh with the major components:
What Is a Data Mesh and How Does It Work?
Think of data mesh as an operational mode for organizations with a domain-driven, decentralized data architecture. It’s a combination of implementation, organizational patterns, and a technology-agnostic set of principles. By pushing the ownership to the product owners of the data, it can better serve the consumers, changing the way data projects are managed within organizations.
According to Zhamak Dehghani, who pioneered the paradigm, key principles of data mesh include:
- Treating data as a product – Empower business units to own and manage their data and provide it to others as a product itself.
- Domain-driven ownership of data – Data is owned by those who create it, understand its nuances, and have the expertise to manage it. Users gain the ability to find, explore, create, and enrich new data sources based on use cases with centralized governance for security and privacy.
- Self-serve data platforms – Allows domain teams to provide self-serve capabilities that reduce the complexity of data creation and consumption of data products.
- Federate trust and computational platform – Serves as an ecosystem where users get value from aggregating and correlating independent data products as the data mesh is created based on interoperability standards.
To understand the principles of data mesh better, and how to best enable it, we need to first discuss the key components including domain, data product, data contracts, and data sharing.
What Is a Domain?
The term domain in a data mesh context is a logical grouping of organizational units fulfilling a functional condition. It’s a set of tasks that the domain is assigned to perform—the reason the domain exists within organizational constraints. In a data mesh, domains are represented by a node, which can be an operational data store (ODS), a data warehouse, or a data lake tailored to the domain’s requirements. Domains can ingest operational data, build analytical data models as data products, and publish them with data contracts to serve other domains’ data needs. Mesh emerges when teams use other domains’ data products and the domains communicate with others in a governed manner.
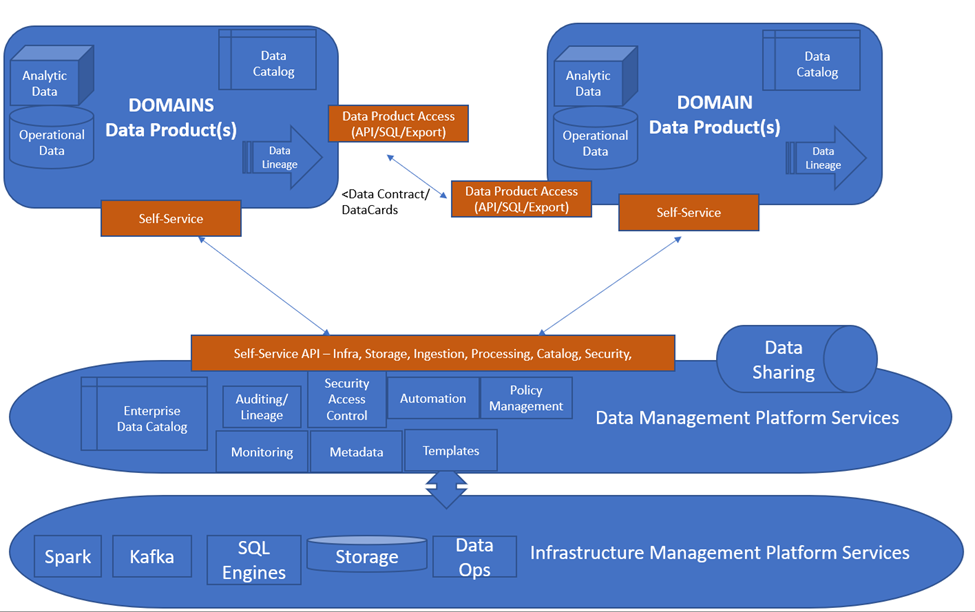
What Is a Data Product and Who Owns Them?
A data product is the node on the mesh that encapsulates code, data, metadata, and infrastructure. They are crafted, curated, and presented to consumers as self-service, providing a reliable and trustworthy source for sharing data across the organization.
Domain-oriented teams own data products and are accountable for managing their service level agreements (SLAs), data quality, and governance. The data product owner is responsible for establishing the mechanisms for allowing data producers and data consumers to interact and transact safely and reliably. The owner also provides infrastructure and mechanisms to permit data producers and consumers to interact.
Figure 2 Shows the concept of a data product:
